Human4DiT: 360-degree Human Video Generation with 4D Diffusion Transformer
Ruizhi Shao*, Youxin Pang*, Zerong Zheng, Jingxiang Sun, Yebin Liu
Tsinghua University
*Equal Contribution
SIGGRAPH ASIA 2024 (Journal Track)
Given a reference image, SMPL sequences and camera parameters, our method is capable of generating free-view dynamic human videos.
[Paper]
[Data]
[Code]
Method
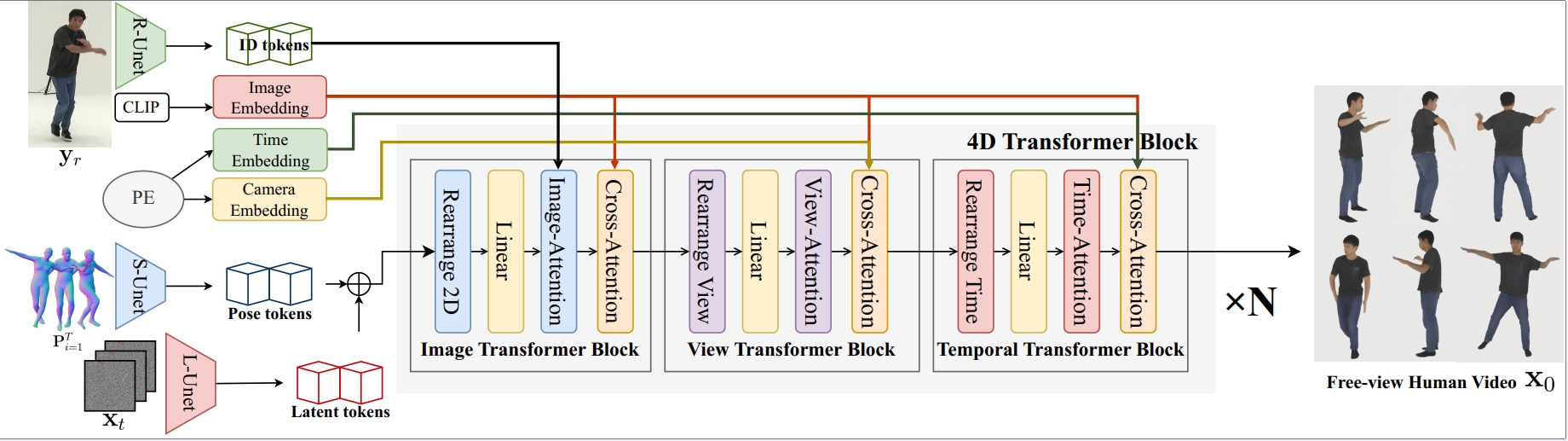
The pipeline of Human4DiT. our framework is based on 4D diffusion transformer, which adopts a cascaded structure consisting of the 2D image, the view transformer, and the temporal blocks.
The input contains a reference image, dynamic SMPL sequences, and camera parameters.
Starting from a generated noisy latent representation, we then denoise it with multiple conditions.
Firstly, the 2D image transformer block is designed to capture spatial self-attention within each frame.
In addition, human identity extracted from reference image is also injected to ensure identity consistency.
Secondly, we use the view transformer block to learn correspondences across different viewpoints.
Finally, we adopt a temporal transformer to capture temporal correlations with time embedding.
Results -- Monocular Video
Results -- Free-view Video
Results -- Static 3D Video
Comparisons -- Monocular Video
Comparisons -- Multi-view Video
Comparisons -- Static 3D Video
Comparisons -- Free-view Video
Ethics Statement
While our method for human video generation could benefit a lot of applications for entertainment, education, and accessibility, we recognize the risks of misuse for creating deepfakes, privacy violations, and perpetuating societal biases. We are committed to responsible development and promoting transparency in our methods. By discussing these ethical considerations, we aim to foster the positive applications of this technology while minimizing potential harm.
Citation
Ruizhi Shao, Youxin Pang, Zerong Zheng, Jingxiang Sun, Yebin Liu. "Human4DiT: 360-degree Human Video Generation with 4D Diffusion Transformer". ACM Trans. Graph. (Proc. SIGGRAPH ASIA) 2024
@article{shao2024human4dit,
title={Human4DiT: 360-degree Human Video Generation with 4D Diffusion Transformer},
author={Shao, Ruizhi and Pang, Youxin and Zheng, Zerong and Sun, Jingxiang and Liu, Yebin},
journal={ACM Transactions on Graphics (TOG)},
volume={43},
number={6},
articleno={},
year={2024},
publisher={ACM New York, NY, USA}
}